Dans cet article, je vous propose de vous présenter Spring Cloud Stream, un projet de Spring Cloud qui permet de simplifier la mise en place de flux de données entre applications.
Principe de fonctionnement
Spring cloud stream se base sur un principe de paire binder / bindings permettant de créer un channel spring integration sur lequel transite les messages sur lesquels on peut appliquer des traitements.
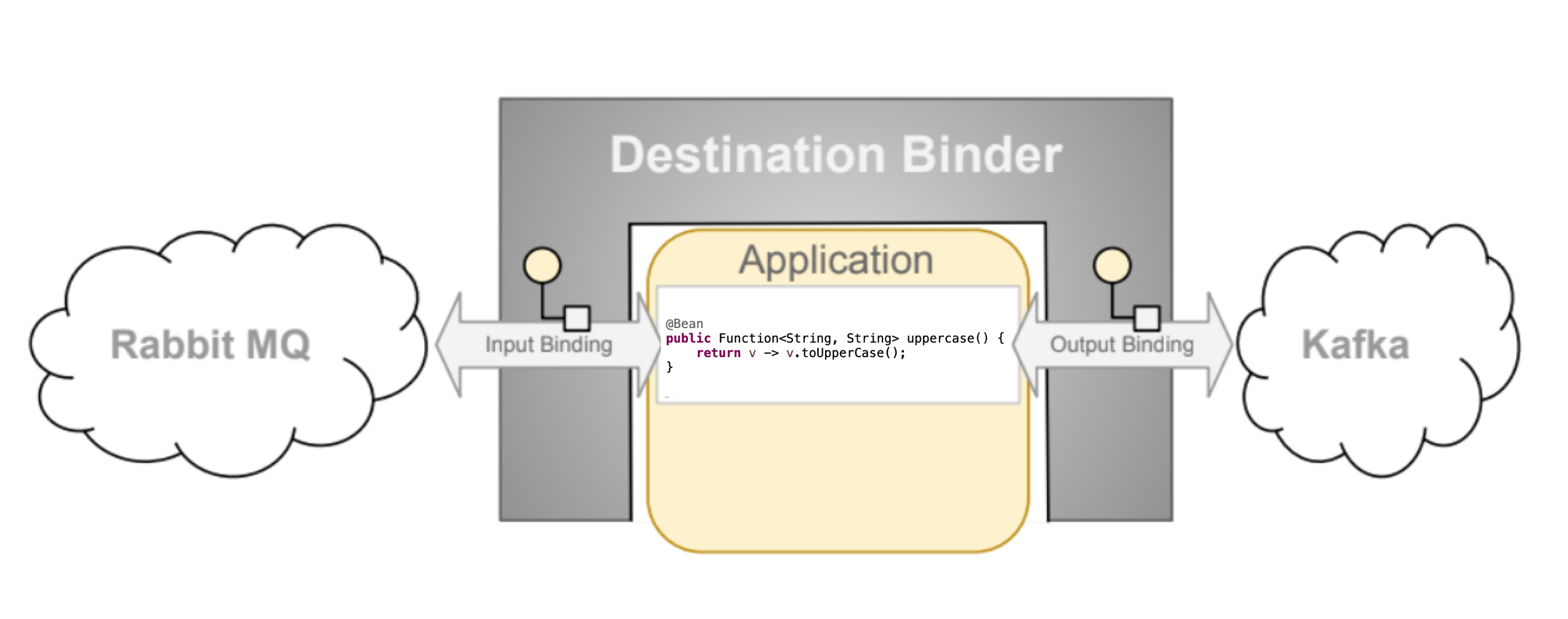
Spring cloud stream s’inscrit comme une alternative à Kafka Stream avec une approche plus abstraite car non liée à Kafka. De plus, ce module de spring cloud peut tout à fait être utilisées pour des applications ne faisant que produire ou consommer des messages.
C’est notamment sur ce genre de usecase que je l’ai utilisé pour des projets chez des clients ; car il permet de ne pas se focaliser sur la technologie de messaging utilisée et de se concentrer sur le traitement des messages.
Exemple d’utilisation
Création d’un projet
Nous allons nous baser sur le projet très simple suivant: “un émetteur envoie un message à un destinataire”.
Sur ce projet, on écrira un traitement qui filtre les messages n’ayant ni destinataire ni contenu. Cela nous permettra d’exploiter les 3 cas d’utilisation de Spring Cloud Stream :
- publication de message,
- consommation de message,
- traitement de message.
Le projet
Vous pouvez retrouver le projet exemple sur github.
Les dépendances
Pour spring cloud stream, nous avons
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
<exclusions>
<exclusion>
<artifactId>commons-logging</artifactId>
<groupId>commons-logging</groupId>
</exclusion>
</exclusions>
</dependency>
</dependencies>Nous avons ici les dépendances pour les 2 binders les plus utilisés : Kafka et RabbitMQ.
NOTE : nous avons exclus
commons-loggingcar il empêche la compilation native du projet avec GraalVM.
La configuration
Pour configurer Spring Cloud Stream, nous avons paramétré les propriétés suivantes dans le fichier application.yml :
schema:
registry:
url: http://localhost:8081
spring:
application:
name: introduction-spring-cloud-stream
rabbitmq:
addresses: localhost:5672
username: guest
password: guest
cloud:
function:
definition: processor;consumer
stream:
kafka:
binder:
brokers: localhost:9092
configuration:
security:
protocol: PLAINTEXT
producer-properties:
schema.registry.url: ${schema.registry.url}
key.serializer: org.apache.kafka.common.serialization.StringSerializer
value.serializer: io.confluent.kafka.serializers.KafkaAvroSerializer
consumer-properties:
schema.registry.url: ${schema.registry.url}
key.deserializer: org.apache.kafka.common.serialization.StringDeserializer
value.deserializer: io.confluent.kafka.serializers.KafkaAvroDeserializer
specific.avro.reader: true
output-bindings: producer
bindings:
processor-in-0:
destination: my-process-topic
group: consumer
contentType: application/*+avro
consumer:
use-native-decoding: true
processor-out-0:
destination: my-result-topic
group: consumer
content-type: application/json
binder: rabbit
consumer-in-0:
destination: my-result-topic
group: consumer
contentType: application/json
binder: rabbit
producer:
destination: my-process-topic
contentType: application/*+avro
producer:
use-native-encoding: trueLa configuration permet de définir le pipeline de traitement suivant :
processor: le traitement qui filtre les messagesproducer: l’émetteur de messageconsumer: le consommateur de message

Cette exemple établit un endpoint REST qui permet d’envoyer un message à un récepteur de message.
Le message est ensuite traité par le traitement processor qui filtre les messages n’ayant ni destinataire ni contenu.
Enfin le résultat du traitement est envoyé à un consommateur qui l’affiche dans la console.
Ce qui est intéressant dans cette configuration, c’est que le traitement processor est totalement indépendant
du binder utilisé. Il est donc possible de changer de système de messaging sans avoir à modifier le traitement.
On ne s’intéresse donc plus qu’au traitement des messages et non plus à la technologie de messaging.
Le code
D’un point de vue code, on va déclarer plusieurs composants.
Le traitement du message
On définit un composant MessageProcessor qui va traiter le message et le filtrer si besoin:
class MessageProcessor {
fun process(message: Message): Result? {
LOGGER.info("Processing messages: {}", message)
val hasNoContent = message.content.isNullOrBlank()
if (hasNoContent) {
LOGGER.debug("Message {} is filter out because it does not have any content", message.id)
return null
}
val hasNoReceiver = message.receiver.isNullOrBlank()
if (hasNoReceiver) {
LOGGER.debug("Message {} is filter out because it does not have any receiver", message.id)
return null
}
return Result(
id = message.id,
timestamp = message.timestamp,
content = message.content,
sender = message.sender,
receiver = message.receiver
)
}
private companion object {
private val LOGGER = org.slf4j.LoggerFactory.getLogger(MessageProcessor::class.java)
}
}L’émetteur de message
On définit un composant MessageProducer qui va envoyer un message sur le channel nommé producer :
class MessageProducer(private val streamOperations: StreamOperations) {
fun produce(message: Message) {
LOGGER.info("Producing message: {}", message)
streamOperations.send("producer", message)
}
private companion object {
private val LOGGER = org.slf4j.LoggerFactory.getLogger(MessageProducer::class.java)
}
}Le consommateur de message
On définit un composant ResultConsumer qui va consommer le message résultant du traitement sur le channel
nommé consumer-in-0 :
class ResultConsumer(private val store: Queue<Result>) {
fun consume(result: Result) {
LOGGER.info("Consuming result: {}", result)
store.add(result)
}
private companion object {
private val LOGGER = getLogger(ResultConsumer::class.java)
}
}Le controller REST
On définit un composant MessageController qui va exposer un endpoint REST permettant d’envoyer un message à un
récepteur de message :
@RestController
class MessageController(
private val idGenerator: Supplier<String>,
private val messageProducer: MessageProducer,
private val clock: Clock
) {
@ResponseStatus(code = NO_CONTENT)
@PostMapping("/{sender}/message")
fun postMessage(
@PathVariable sender: String,
@Valid @RequestBody messageRequestBody: MessageRequestBody
) {
LOGGER.info("Requesting message: {}", messageRequestBody)
val message = Message.newBuilder()
.setId(idGenerator.get())
.setTimestamp(clock.instant().toEpochMilli())
.setContent(messageRequestBody.content)
.setSender(sender)
.setReceiver(messageRequestBody.receiver)
.build()
LOGGER.info("Sending message: {}", message)
messageProducer.produce(message)
}
private companion object {
private val LOGGER = getLogger(MessageController::class.java)
}
}Lancement du projet
Pour lancer le projet, il faut lancer le serveur de schema registry :
./mvnw spring-boot:runA partir de là, on peut envoyer un message à un récepteur de message en appelant l’ endpoint REST suivant :
curl -X POST \
http://localhost:8080/sender1/message \
-H 'Content-Type: application/json' \
-d '{
"content": "Hello World",
"receiver": "receiver1"
}'Et voilà, vous venez de développer votre première petite application spring cloud stream. 🚀
Les tests
Un avantage de spring cloud stream est qu’il abstrait le système de messaging utilisé. Cela permet donc à spring cloud stream d’introduire un binder in memory qui permet de tester facilement les composants.
Dépendances
Pour cela, il suffit d’ajouter la dépendance suivante :
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-test-support</artifactId>
<scope>test</scope>
</dependency>Configuration
Pour dans la partie testing, on reprendra la configuration de notre application tout en prenant soin de ne pas placer le binder Kafka ou RabbitMQ :
spring:
application:
name: introduction-spring-cloud-stream
cloud:
function:
definition: processor;consumer
stream:
output-bindings: producer
bindings:
processor-in-0:
destination: my-process-topic
group: consumer
contentType: application/*+avro
consumer:
use-native-decoding: true
processor-out-0:
destination: my-result-topic
group: consumer
content-type: application/json
consumer-in-0:
destination: my-result-topic
group: consumer
contentType: application/json
producer:
destination: my-process-topic
contentType: application/*+avro
producer:
use-native-encoding: trueLe code de test
On peut ensuite tester notre application en utilisant le binder in memory :
@AutoConfigureMockMvc
@SpringBootTest
class IntroductionSpringCloudStreamApplicationTests {
@Autowired
private lateinit var mockMvc: MockMvc
@Autowired
private lateinit var store: Queue<Result>
@Test
fun `should consume message with content from sender to receiver`() {
this.mockMvc.perform {
post("/sender/message")
.contentType("application/json")
.content(
"""
{
"content": "Hello World!",
"receiver": "receiver"
}
""".trimIndent()
)
.buildRequest(it)
}.andExpect { status().isOk }
val result = this.store.peek()
assertThat(result).isNotNull
assertThat(result.id).isNotNull
assertThat(result.content).isEqualTo("Hello World!")
}
}Compilation native
Une petite particularité de Spring Cloud Stream est qu’il est possible de compiler le projet en binaire natif avec GraalVM.
Pour cela, il faut ajouter la dépendance suivante :
<plugins>
<plugin>
<groupId>org.graalvm.buildtools</groupId>
<artifactId>native-maven-plugin</artifactId>
</plugin>
</plugins>Si vous êtes sous MacOS comme moi et que vous utilisez les processors ARM (Mx) alors il faut changer le builder buildpacks
pour utiliser le builder dashaun/builder:tiny :
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<image>
<builder>dashaun/builder:tiny</builder>
</image>
</configuration>
</plugin>
</plugins>Une fois tout cela effectué, vous pouvez construire votre image native avec la commande suivante :
./mvnw spring-boot:build-imageOu alors compiler votre projet pour obtenir un livrable executable avec la commande suivante :
./mvnw -Pnative native:compileUne fois le livrable généré, vous pouvez lancer votre application avec la commande suivante :
./target/introduction-spring-cloud-streamMalheureusement dans mon cas, j’ai eu une erreur lors du lancement de l’application :
2024-01-07T15:35:55.791+01:00 ERROR 9016 --- [introduction-spring-cloud-stream] [ main] o.s.cloud.stream.binding.BindingService : Failed to create consumer binding; retrying in 30 seconds
org.springframework.cloud.stream.binder.BinderException: Cannot initialize binder checking the topic (my-process-topic):
at org.springframework.cloud.stream.binder.kafka.provisioning.KafkaTopicProvisioner.getPartitionsForTopic(KafkaTopicProvisioner.java:684) ~[introduction-spring-cloud-stream:4.1.0]Pour l’instant, j’ai l’impression que la compilation native ne semble pas encore fonctionnelle avec spring cloud stream ; donc faites comme moi et stay tuned ! 🤞
Conclusion
Spring Cloud Stream est un projet très intéressant qui permet de simplifier la mise en place de flux de données entre applications.
Il permet de se concentrer sur le traitement des messages et non plus sur la technologie de messaging utilisée.
Un autre avantage d’utiliser spring cloud stream, c’est qu’il nous permet de très facilement tester notre système sans se préoccuper de devoir installer un système de message qui est souvent lourd à faire lorsque l’on souhaite lancer nos tests automatisés.